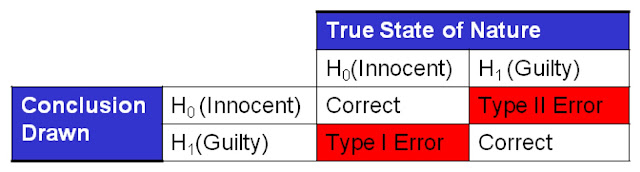
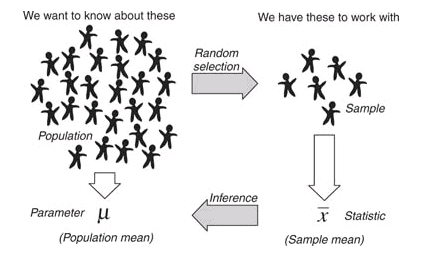
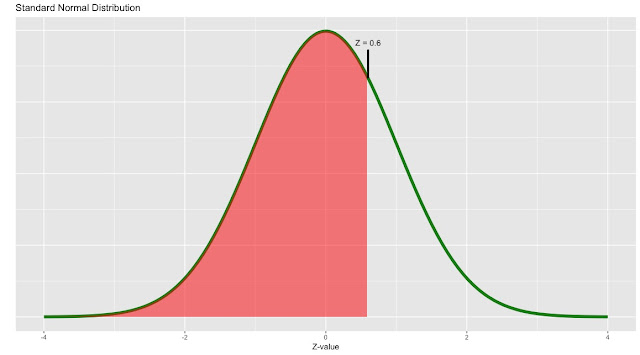
Learn to Code in R: Introduction to R and Basic Concepts.
There are many options when it comes to statistical computing, but R is freely available, powerful, robust, and always getting better. Most statistical software packages have exorbitant costs associated with obtaining personal or group licenses. But with R, you get an extremely powerful software package that is just as good, if not better, for no cost! This software is ever-improving and growing thanks to the many people who contribute to this project and make this all possible. This post is designed to be a first time exposure to R for those with no experience and want to start learning how to code. Whether you are a student in a stats course trying to learn or are trying to acquire a little R know-how in order to expand you business intelligence skills, this post is designed to help people get started. In this post, I will be giving you a basic knowledge of R skills so you can start doing simple analyses quickly. Specifically, I will be covering How to acquire R and Rstudio. Rs...